
DPO Optimized Reinforcement Learning of LLM for Mathematical Purposes
Published:
Authors: Chaitanya varma Siruvuri\(^1\), Gowthamvenkata Sai Maddala\(^2\), Vummadi Harsha Vardhan Reddy\(^3\)
1. Stony Brook University, 2. Stony Brook University,3. Stony Brook University
Abstract
Large Language Models (LLMs) have transformed software development, but they often struggle with complex programming tasks. This research introduces a new approach using Direct Preference Optimization (DPO) to enhance the complex reasoning and debugging capabilities of LLMs in Python. We fine-tuned the Qwen 2.5 3B model with DPO using specially curated datasets. Through careful hyper-parameter tuning and an optimized training process, the model’s performance on programming and debugging tasks increased from 45% to 61%, a 35.56% improvement. This work sets a new standard for AI-assisted software development and provides valuable insights into how model architecture, size, and fine-tuning methods interact.
Introduction
While Large Language Models (LLMs) have made significant strides in automating programming tasks, they often fall short when dealing with the precision and complex reasoning required for intricate Python programming. Traditional methods for aligning these models with user needs, such as Reinforcement Learning from Human Feedback (RLHF), are computationally expensive and not always effective for specialized domains like data science. Direct Preference Optimization (DPO) offers a more efficient solution. Unlike RLHF, DPO directly optimizes a model to satisfy human preferences using a classification objective, which eliminates the need for a separate reward model and the complexities of reinforcement learning. This streamlined process enhances both computational efficiency and alignment fidelity, making it ideal for tailoring models to specialized tasks. This research applies DPO to the Qwen 2.5 model to improve its Python programming, reasoning, and debugging skills, addressing key limitations in current AI-assisted development
Objective
The primary objective of this project is to enhance the advanced reasoning and debugging capabilities of Large Language Models for complex Python programming tasks. The core goals were to: Implement DPO: Apply Direct Preference Optimization to fine-tune an advanced LLM (Qwen 2.5 3B) on specialized Python datasets. Curate a High-Quality Dataset: Construct a comprehensive preference dataset of approximately 12,000 high-quality triplets, each containing a prompt, a preferred (chosen) response, and a rejected response for Python reasoning and debugging problems. Optimize Fine-Tuning: Employ efficient fine-tuning techniques like Low-Rank Adaptation (LoRA) as a pre-finetuning step to manage computational overhead while adapting the model to specific tasks. Evaluate Performance: Measure the model’s improvement through rigorous evaluation, comparing its performance before and after DPO fine-tuning on a set of hand-picked reasoning and debugging problems. Analyze and Benchmark: Compare the results against other models, such as Llama 3.1 and Llama 3.2, to understand the relationship between model architecture and the effectiveness of DPO
Methdology
The methodology is centered around a robust fine-tuning framework designed to align the language model with specific programming objectives. Dataset Construction: The process began with the creation of a specialized dataset. This involved extracting and filtering data from various sources and combining it with a custom-curated set of debugging problems. The final dataset consists of triplets in the format (x,y c ,y r ), where ‘x’ is the prompt, ‘y c ‘ is the chosen (preferred) response, and ‘y r ‘ is the rejected response.
Low-Rank Adaptation (LoRA): Before DPO, we used LoRA as an efficient pre-fine-tuning technique. LoRA introduces trainable low-rank matrices, allowing the model to adapt to new tasks with minimal computational cost by only training these new matrices while keeping the original model weights frozen. Direct Preference Optimization (DPO): Following LoRA, the model was fine-tuned using DPO. This process directly optimizes the model based on the preference data by minimizing the DPO loss function, which is designed to increase the likelihood of preferred responses while decreasing the likelihood of rejected ones. KL Penalty for Regularization: To prevent overfitting and ensure the model’s stability, a Kullback-Leibler (KL) penalty was used as a regularization technique. This constrains the fine-tuned model from deviating too far from the original pre-trained model, preserving its general knowledge while incorporating task-specific skills. 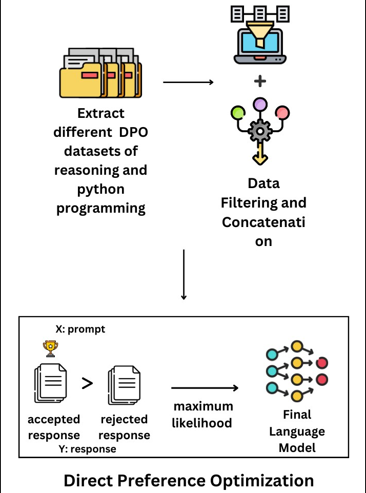
An overview of the Direct Preference Optimization (DPO) training methodology.
Results and Conclusion
The performance of different LLMs was evaluated on 100 hand-picked reasoning and debugging problems before and after DPO fine-tuning.
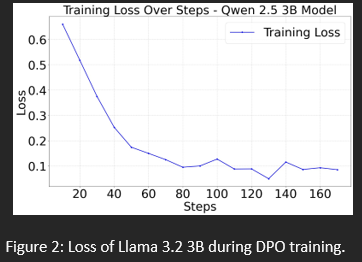
Figure 7: Training loss of the Qwen 2.5 3B model during DPO.
Qwen 2.5 3B: This model showed the most significant improvement, with its score increasing from 45 to 61 correct solutions, a 36% (35.56% in abstract) gain. This highlights the effectiveness of DPO when applied to a model with a flexible and receptive architecture.
Future Scope
Future work will aim to build upon these findings to further refine AI-assisted programming tools. Key directions include: Hybrid Alignment Approaches: Explore hybrid methods that combine the benefits of DPO with other techniques to better preserve task-specific accuracy while optimizing for general user preferences. Advanced Dataset Curation: Expand the preference datasets to cover an even wider range of complex programming and debugging scenarios to improve model robustness. Architectural Analysis: Conduct deeper investigations into why certain model architectures, like Qwen’s, are more receptive to DPO fine-tuning for reasoning tasks compared to others. Broader Domain Application: Apply the DPO fine-tuning methodology to other precision-driven fields beyond Python, such as formal verification, scientific computing, and other programming languages.