
Modular Framework for Advanced Personalized video summarization using LLMs
Published:
Authors: Ashwitha Bukka\(^1\), Sharmukh Reddy Atluru\(^2\), Vummadi Harsha Vardhan Reddy\(^3\)
1. Stony Brook University, 2. Stony Brook University,3. Stony Brook University
Abstract
To address the challenge of providing scalable personalized education, this project introduces an innovative framework that combines Large Language Models (LLMs) with open-source speech processing tools. The system creates tailored video summaries and learning materials by building detailed learner profiles from academic data like learning records, assessments, and teacher observations. It processes instructional video content by using OpenAI’s Whisper for accurate speech recognition and employs LLMs to infer speaker roles, enriching the contextual understanding. An LLM-powered summarization module then produces personalized summaries. This privacy-focused design ensures that raw data remains controlled by the instructor and achieves near real-time performance, demonstrating a practical approach to creating learner-aware educational experiences.
Introduction
Accommodating the diverse learning preferences and abilities of students is a persistent challenge in education. Standardized instruction often leads to disengagement because it fails to address these individual differences. While educational videos are a scalable resource, they typically lack the personalization needed to keep learners motivated. This project introduces a cost-effective and scalable system that leverages LLMs and retrieval-augmented generation to deliver personalized educational video content. The process starts by transcribing audio from educational videos using Whisper, a state-of-the-art speech recognition model known for its high accuracy
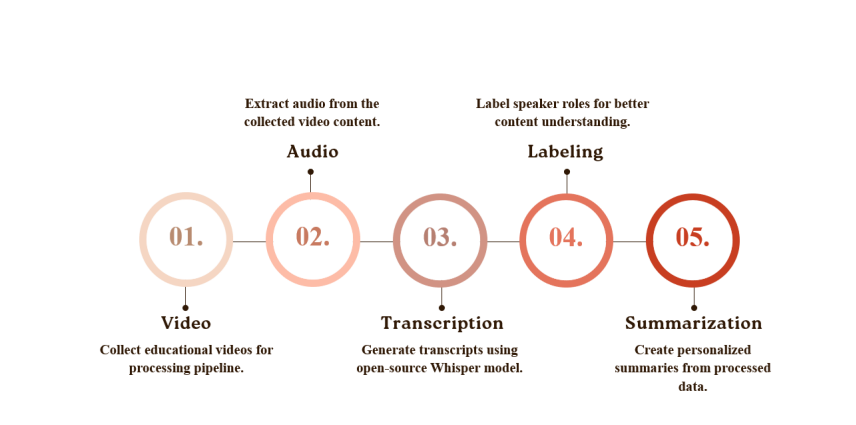
Figure 1: The 5-step project pipeline from video collection to summarization.
To better understand the content, speaker roles are identified using
Claude 3 Haiku. Concurrently, comprehensive student profiles are created from various data sources and are converted into dense vector embeddings that capture learning styles, goals, and challenges. The video transcripts are also chunked and embedded, then indexed in the
Pinecone vector database for efficient retrieval of content relevant to each learner. Finally, Claude 3 Haiku synthesizes this information to generate personalized summaries.
Objective
The primary goal of this project is to develop and implement a modular system that transforms generic educational videos into customized learning experiences. The system is designed to: Ingest and Transcribe: Automatically process educational videos to generate accurate, timestamped transcripts using the Whisper ASR model. Create Learner Profiles: Construct detailed student profiles from academic history, goals, and challenges, and convert them into semantic vector embeddings. Personalize Content: Use a retrieval-augmented generation (RAG) approach to match video content with individual learner profiles. Generate Summaries: Employ an LLM (Claude 3.5 Haiku) to produce abstractive, personalized summaries that are tailored to each student’s specific needs and learning context. Ensure Practicality: Deliver a system that is efficient, with a processing time of under 30 seconds for a 20-minute video, and deployable in a manner that respects student privacy.
Methdology
The system architecture is a modular pipeline that integrates state-of-the-art NLP and speech recognition technologies. Video Ingestion and Preprocessing: The process starts by ingesting educational videos. The audio is extracted, cleaned using FFmpeg to reduce noise and normalize sound, and prepared for transcription. 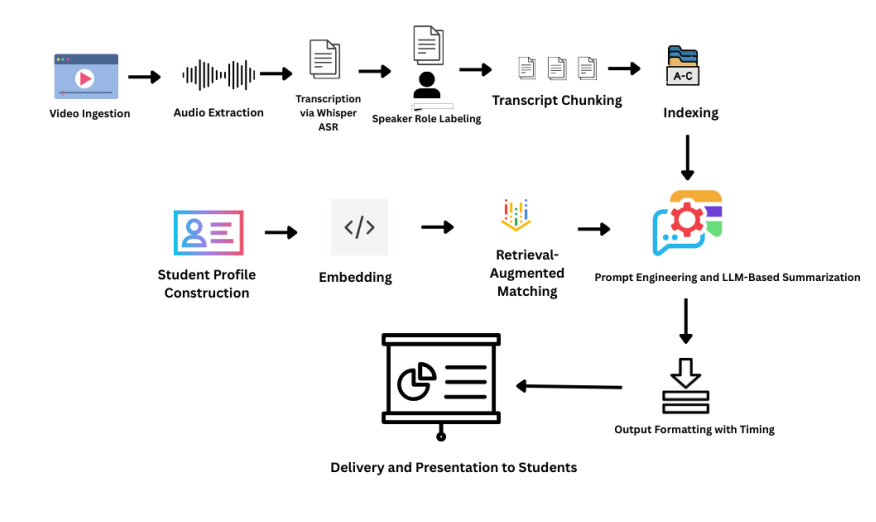
Figure 3: The end-to-end technical architecture of the summarization system.
Transcription and Speaker Labeling: The audio is transcribed using OpenAI’s Whisper model to generate timestamped text. For multi-speaker videos, Claude 3 Haiku is used to analyze linguistic cues and assign roles like “Instructor” or “Student” to different parts of the transcript. Embedding and Indexing: The transcript is broken into semantic chunks. These chunks, along with the student profiles, are converted into vector embeddings using Sentence Transformers. All transcript embeddings are indexed in Pinecone, a vector database optimized for fast similarity searches. 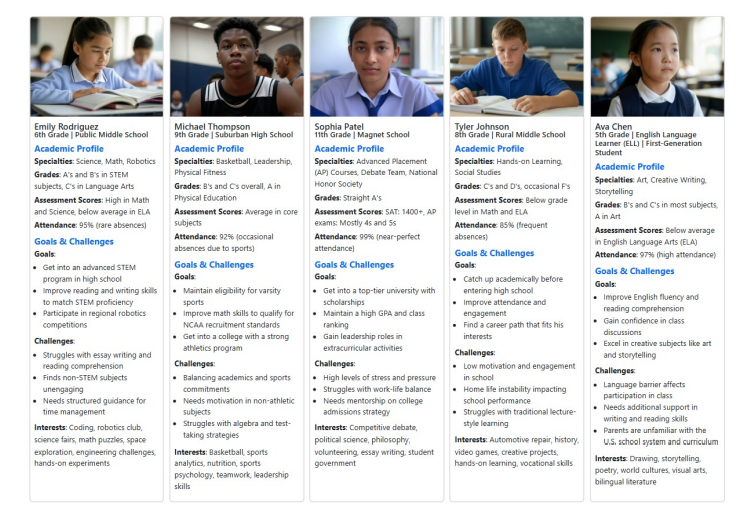
Figure 2: The five student personas created to guide project development.
Retrieval and Summarization: For a given student, their profile vector is used to query Pinecone, retrieving the most relevant transcript chunks. These chunks and the student’s profile are then fed to Claude 3.5 Haiku, which generates a personalized, abstractive summary. Output and Delivery: The final summary is delivered in a structured JSON format, including timestamps, allowing it to be integrated into various learning interfaces
Results and Conclusion
The system’s effectiveness was validated through both quantitative metrics and qualitative analysis. Transcription Quality: The Whisper model achieved a Word Error Rate (WER) of 8.7% and a Character Error Rate (CER) of 4.2%, demonstrating high accuracy in converting speech to text. 
Figure 5: Transformation of a generic transcript into actionable, personalized highlights.
Summary Quality: The personalized summaries were evaluated using ROUGE scores, yielding a ROUGE-1 F1 of 0.524, which indicates a strong lexical overlap with human-written reference summaries. 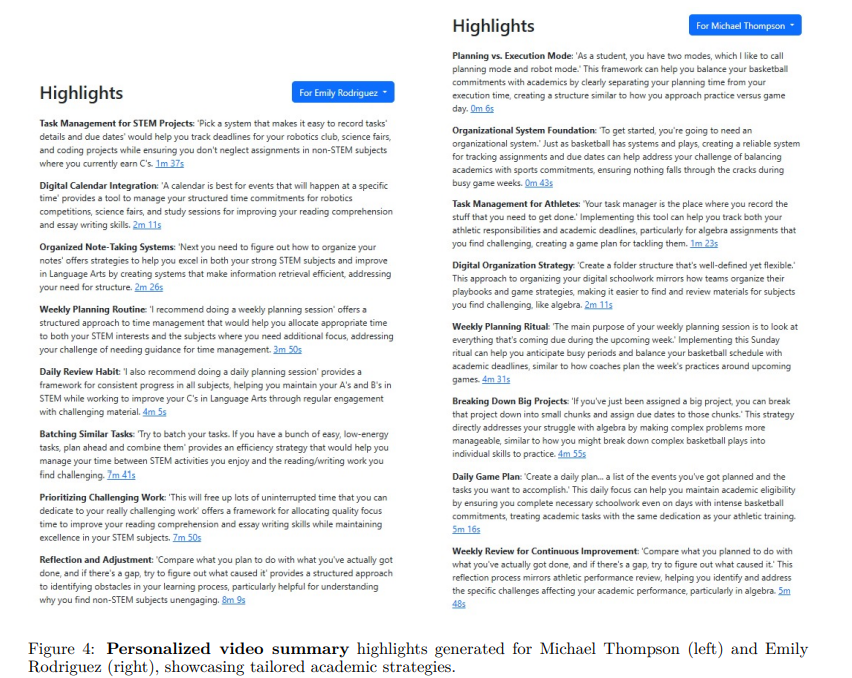
Figure 4: Personalized video summary highlights generated for two different students.
Personalization: As demonstrated with student profiles like Michael Thompson (an athlete) and Emily Rodriguez (a STEM-focused student), the system successfully tailored the same video content to meet different needs. Michael’s summary used sports metaphors to explain concepts, while Emily’s focused on structured guidance for her academic challenges. In conclusion, this project presents a reliable and efficient framework for creating personalized educational video summaries at scale. By integrating advanced AI tools, the system effectively bridges the gap between generic instructional content and the unique learning needs of individual students. The low-cost, privacy-conscious design offers a practical solution for enhancing student engagement and promoting more inclusive learning environments.
Future Scope
Future work will focus on enhancing the system’s capabilities and broadening its impact. Key areas for development include: Multimodal Summarization: Integrating visual cues from videos, like diagrams and gestures, using Multimodal Large Language Models (M-LLMs). Real-Time Personalization: Developing dynamic summaries that adapt in real-time based on learner interactions, such as pausing or re-watching video segments. Instructor Feedback Loop: Allowing educators to review and customize summaries to align with specific curriculum goals. Interactive Learning: Integrating conversational agents to allow students to ask follow-up questions about the video content, transforming the tool into an interactive learning assistant.